How LinkedIn Rebuilt Service Discovery to Scale to Millions of Services
LinkedIn rebuilt service discovery using Kafka and Observer, enabling scalable, push-based updates with lower latency and higher availability.
When you open LinkedIn and scroll your feed, send a message, or load notifications, a lot more is happening behind the scenes than you might expect. Each action triggers multiple services talking to each other. Now imagine this at LinkedIn scale with tens of thousands of microservices, running across global data centers, handling billions of requests daily. The question is, “How do all these services find and talk to each other reliably?” The answer lies in something called service discovery and LinkedIn recently rebuilt this system from scratch. Let’s discover what it is and how LinkedIn rebuilt it in this blog today.
What is Service Discovery
You can think of service discovery like a directory. If one service wants to talk to another, it needs to know where that service is running, its IP address and port.
But in modern systems services keep scaling up/down and instances keep changing. So hardcoding locations doesn’t work. Instead:
Services register themselves in a central system
Other services query this system to find them
This central system is called the control plane.
Old System: Zookeeper-Based Architecture
For years, LinkedIn used Apache ZooKeeper as its service discovery control plane. Here’s how it worked:
Services register their endpoints in ZooKeeper
Clients read this data directly
ZooKeeper also performs health checks
This sounds simple and it worked well initially. But as LinkedIn scaled, cracks started to appear.
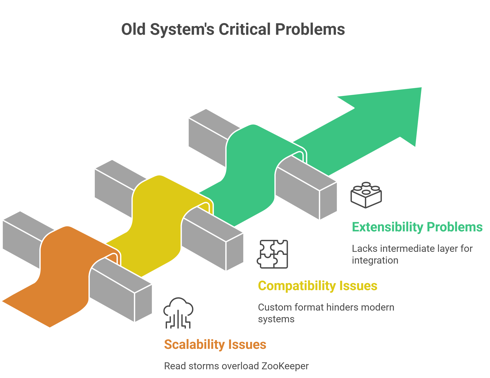
Problems with the Old System

1. Scalability Issues
ZooKeeper handled all reads, all writes and all health checks in one place and this created a bottleneck.
During large deployments service data changed frequently and thousands of clients started reading updates which caused read storms (massive spikes in read requests). Since ZooKeeper enforces strong consistency, everything goes through a single queue. So when reads increase:
writes get delayed
health checks fail
sessions drop
And as a result service instances get removed, capacity drops and systems become unavailable.
2. Compatibility Issues
LinkedIn used a custom format (D2), which didn’t work well with modern systems like gRPC or Envoy and it was heavily Java-centric.
This made:
multi-language support difficult
onboarding new systems harder
3. Extensibility Problems
The architecture lacked an intermediate layer. So it was hard to:
add centralized load balancing
integrate with Kubernetes
evolve the system
New System: Next-Gen Service Discovery
To solve these issues, LinkedIn built a completely new system. Instead of one monolithic control plane, they introduced a decoupled architecture.
Key Components
Kafka (Write Path): Services now send updates via events to Apache Kafka. These include service registrations and heartbeats.
Service Discovery Observer (Read Path): A new component called Observer:
consumes events from Kafka
stores data in memory
serves clients
gRPC Streams: Clients:
open persistent connections using gRPC
receive updates in real time
The key shift was moving from a pull-based model (clients fetching data) to a push-based model where the Observer streams updates to clients in real time.
Why this Architecture Works Better
1. Scalability
Observer is horizontally scalable and highly concurrent. Thus one Observer can:
handle 40K client connections
process 10K updates/sec
2. Availability Over Strict Consistency
The shift was from prioritizing strong consistency in ZooKeeper to favoring availability with eventual consistency in the new system.
This means:
small inconsistencies are okay temporarily
system stays responsive
3. Fault Tolerance
Even if Kafka is slow or down, observer serves cached data. So services still function with no downtime.
Dual Mode
Replacing a core system like service discovery is risky. So LinkedIn didn’t switch everything at once.
They used Dual Mode (Dual Read + Dual Write)
Dual Read
clients read from both old (ZK) and new system
compare results in background
Dual Write
services register in both systems
This approach is powerful because it verifies correctness, catches mismatches early, and prevents issues from impacting production.
Observability: The Backbone of Migration
To ensure everything works, LinkedIn added deep monitoring.
They tracked:
connection health
latency
data consistency
system resource usage
Metrics
End-to-end propagation latency improved from P50 < 10s and P99 < 30s in the old system to P50 < 1s and P99 < 5s in the new system
New system:
P50 < 1s
P99 < 5s
Earlier system:
P50 < 10s
P99 < 30s
And that’s some crazy improvement!
Migration Dependencies
One of the trickiest challenges was migration dependency because clients needed to move first, but write migration depended on read migration, creating a dependency loop.
Solution
LinkedIn:
analyzed dependency graphs
tracked which services depend on others
migrated carefully in phases
They also built tools to detect regressions and monitored which apps still relied on old system.
Takeaways
Decouple read and write paths Separating Kafka (write path) and Observer (read path) removes bottlenecks and allows each side to scale independently.
Prefer push over pull at scale Instead of clients repeatedly polling for updates, streaming changes via persistent connections reduces load and improves latency.
Prioritize availability over strict consistency (when appropriate) In systems like service discovery, it’s more important to stay responsive than perfectly consistent at every moment.
Design for multi-language ecosystems Using standards like gRPC and xDS makes the system compatible across different languages and frameworks.
Migrate critical systems gradually Techniques like dual read and dual write help validate the new system safely without risking production stability.
Official blog from LinkedIn: Scalable, multi-language service discovery at LinkedIn
By now, you must have had a clear idea of, How LinkedIn Rebuilt Service Discovery to Scale to Millions of Services? In a nutshell, LinkedIn replaced its ZooKeeper-based service discovery with a Kafka + Observer system to handle massive scale more reliably. By shifting to a push-based, scalable architecture, it improved latency, availability, and multi-language support.
Congratulations! You've just advanced another step in your tech journey. Keep progressing!
Rohit Lakhotia
Rohit Lakhotia is a software engineer and writer covering engineering, career growth, and the tech industry.