How Nomad by HashiCorp Reduced Scheduler Load by 90%
Nomad reduces scheduler load by canceling redundant evaluations, improving system performance and speeding up recovery during failures.
Imagine you're running a large distributed system with thousands of machines and jobs. Suddenly, something goes wrong maybe a network glitch or a chunk of servers goes offline. Now your system starts panicking. Not because it’s broken but because it has too much work to do at once. This is exactly the kind of problem HashiCorp Nomad faced. Let’s discover how they solved it in this blog today.
What is HashiCorp Nomad?
Before we jump into the problem and solution, let’s understand what Nomad actually is.
Nomad is a workload orchestrator. That’s just a fancy way of saying, “It automatically runs your applications on a bunch of machines and keeps them running.“
You tell Nomad what you want: “Run 10 instances of my app”
And Nomad ensures:
Apps are deployed on available servers
Failed apps are restarted
System always stays in the desired state
It matters a lot because in large systems, servers fail, apps crash and traffic changes and Nomad handles all of this automatically, making systems scalable and resilient.
What Problem is Nomad Solving?
At a high level, Nomad is a cluster scheduler.
You tell it: “Hey, I want these applications running across my machines.”
Nomad ensures the actual state = desired state. Whenever something changes (like a server crash or new node joining), Nomad needs to recalculate what to do next.
This recalculation happens through something called an evaluation.
What is an Evaluation?
You can think of an evaluation as “A unit of work that decides how to fix the system”
Whenever something changes:
A job fails
A node goes offline
A new node joins
Nomad creates evaluations to figure out, “What changes should I make to bring the system back to the desired state?”
These evaluations are:
Stored in Raft Consensus Algorithm (a distributed log)
Processed by multiple schedulers running across servers
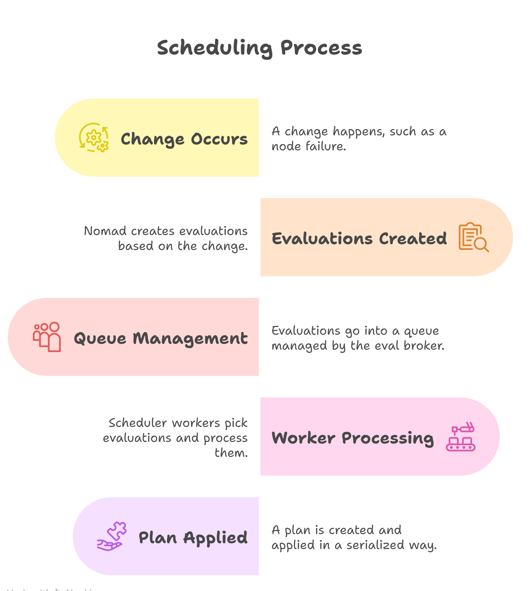
How Scheduling works Internally

Here’s a simplified flow:
A change happens (e.g., node failure)
Nomad creates evaluations
Evaluations go into a queue managed by the eval broker
Scheduler workers pick evaluations and process them
A plan is created and applied (in a serialized way)
Important detail to note is that:
Scheduling is concurrent
But applying results is serialized
This ensures High throughput and Consistency
The Real Problem: Evaluation Explosion
Everything works fine… until large-scale failures happen.
Let’s say:
5,000 nodes
Each running multiple jobs
Now imagine: 10% of nodes go offline
What happens? Nomad creates evaluations like this:
For service jobs → per allocation
For system jobs → per node
This leads to something like: 60,000 evaluations instantly created
And in worse cases? Millions of evaluations
Why this is Dangerous
This creates a perfect storm:
Scheduler Overload: Schedulers now need to process every evaluation
Raft Overload: Each evaluation is written to Raft → replicated across node
Worst Timing: This happens during failures, when the system is already stressed
So instead of fixing the issue quickl, the system slows down trying to process redundant work.
Key Insight that Changed Everything
The Nomad team realized something very important: Evaluations are idempotent for a given state. Which means if you run the same evaluation multiple times on the same cluster state, you get the same result.
Imagine 100 evaluations for the same job:
Only 1 evaluation actually matters
The other 99 are wasted work
Why Not Stop Creating Evaluations?
You might think: “Just don’t create duplicate evaluations!”
But it’s not that simple. Why? Because Nomad is Distributed and Concurrent
There’s no safe way to:
Check globally if an evaluation already exists
Without locking the system (which would hurt performance)
So they needed a smarter solution.
The Smart Fix: Drop Work Later, Not Earlier
Instead of preventing evaluations from being created, they decided to drop unnecessary ones later. This happens inside the eval broker.
Inside the Eval Broker
The eval broker manages multiple queues:
Pending Queue: Waiting evaluations
Ready Queue: Next evaluations to process
Unacked Queue: Currently being processed
One critical rule is that, Nomad ensures: Only one evaluation per job is active at a time
The New Optimization
Here’s the breakthrough:
Once an evaluation is processed (acknowledged), All other pending evaluations for that job become redundant
So Nomad:
Moves them to a cancelable set
Uses a reaper process to clean them up in batches
Marks them as canceled in Raft
What is the Reaper?
Think of it as a background cleaner:
Runs periodically
Also triggered when evaluations are completed
Cancels large batches efficiently
This is powerful because instead of Processing 50,000 evaluations, it process only ~10–20 meaningful ones and cancel the rest in bulk.
Results
Let’s compare before vs after.
Before Optimization
50,000 evaluations processed
Took ~40 minutes
~50,000 Raft logs written
System even missed heartbeats due to load
After Optimization
Only ~20 evaluations processed
Completed in ~90 seconds
Only ~128 Raft logs written
That’s 0.2% of previous load
During Failure Scenario
Before it used to take 13 minutes to recover and approximately 43,000 logs After it was roughly taking 3 minutes and approximately 19,000 logs (much lower load)
Impact
Scheduler load reduced by 99%
Raft load reduced by 80%+
Recovery time improved by ~90%
Takeaways
Idempotency Is Gold: If operations are idempotent,
You can safely drop duplicates
You can optimize aggressively
2. Don’t Always Prevent, Sometimes Clean Up
Instead of: Preventing redundant work upfront (complex), allow it and then clean it efficiently later
3. Batch Processing Saves Systems
The reaper cancels evaluations in bulk:
Fewer writes
Less network overhead
Better performance
4. Optimize for Failure Scenarios
Most systems are designed for Normal conditions. But real-world systems fail. Nomad optimized for Worst-case scenarios.
5. Distributed Systems Need Trade-offs
Nomad chose:
Simplicity in creation
Optimization in processing
Instead of complex coordination upfront
What looks like a small internal change actually transforms system behavior under stress.
Nomad didn’t just Improve performance, It made the system more resilient, faster to recover and better under real-world failures.
Official blog from HashiCorp: Load shedding in the Nomad eval broker
By now, you must have had a clear idea of, How Nomad by HashiCorp Reduced Scheduler Load by 90%? In a nutshell, Nomad optimized its scheduler by dropping redundant evaluations using idempotency, instead of processing all of them. This reduced system load drastically and improved recovery time during failures.
Congratulations! You've just advanced another step in your tech journey. Keep progressing!
Rohit Lakhotia
Rohit Lakhotia is a software engineer and writer covering engineering, career growth, and the tech industry.