How Uber Uses Pull-Based Ingestion to Keep Search Data Fresh at Massive Scale
Uber uses Kafka-based pull ingestion in OpenSearch to handle traffic spikes, simplify recovery, and maintain global search consistency.
Search is one of the most critical components of Uber's platform. Whether you're searching for a restaurant, entering a destination, or tracking a nearby driver, search is often the first interaction a user has with the system.
Behind the scenes, Uber's search platform is indexing enormous amounts of constantly changing data:
Restaurant menus
Delivery information
Locations
Driver availability
Courier updates
Since all of this information changes continuously, Uber's search platform must ensure that data is always fresh, highly available, and scalable. To achieve this, Uber built its search architecture around two core principles:
Pull-based ingestion
Active-active deployment across multiple regions
Let’s discover how Uber moved toward pull-based ingestion, how they contributed this capability to OpenSearch, and how it helps power a globally distributed search platform in this blog today.
The Problem with Traditional Push-Based Indexing
Most search systems use a push-based architecture. In this model, applications directly send indexing requests to the search cluster using HTTP or gRPC.
At first glance, this seems straightforward:
Application
↓
Search Cluster
↓
Index DocumentsHowever, as systems grow, this model starts creating challenges.
Challenge 1: Handling Traffic Spikes: Imagine a sudden surge in traffic. Perhaps a major event causes thousands of new indexing requests to arrive simultaneously. In a push-based system, if the search cluster cannot keep up:
Requests get rejected
Clients receive errors
Applications must implement retry logic
Every team becomes responsible for handling backpressure
This significantly increases operational complexity.
Challenge 2: No Priority Control: Not all indexing requests are equally important.
For example:
Updating a driver's live location is highly time-sensitive.
Bulk updates to older restaurant data may be less urgent.
A traditional push-based API treats both requests the same. During heavy ingestion workloads, critical real-time updates can be delayed by less important traffic.
Challenge 3: Replaying Data Is Difficult: Search systems often need to replay historical data.
Common scenarios include:
Restoring a cluster from a backup
Migrating to a new cluster
Rebuilding indexes
In a push-based architecture, replaying data requires building additional tooling and coordinating the process manually. This makes migrations and recovery significantly more complicated.
Why Uber Chose Pull-Based Ingestion
Instead of applications pushing data directly into the search cluster, Uber flipped the model. Applications write data into Kafka. The search cluster then pulls data from Kafka at its own pace.
Applications
↓
Kafka
↓
OpenSearchThis seemingly simple change solves several problems.
Traffic Spikes Become Easier to Handle: Kafka acts as a durable buffer. When ingestion traffic suddenly spikes:
Kafka absorbs the additional load
Messages remain safely stored
OpenSearch continues consuming at a sustainable rate
Instead of generating errors, the system simply accumulates temporary lag and catches up later.
Better Reliability: Because Kafka persists messages:
Data is not lost
Systems can replay messages whenever necessary
Recovery becomes much simpler
The stream itself becomes the source of truth.
Simpler Migrations: Need to migrate to another cluster or Need to rebuild an index? Simply replay the Kafka stream. No complex replay tooling is required.
Bringing Pull-Based Ingestion to OpenSearch
To make pull-based ingestion a native capability, Uber contributed a dedicated ingestion framework to OpenSearch. This feature was introduced as an experimental release in OpenSearch 3.0 and adds the necessary components for consuming data directly from streaming platforms instead of relying on traditional push-based indexing.
Ingestion Plugin: At the center of this architecture is the IngestionPlugin. This allows OpenSearch to integrate with streaming systems. Today, the framework supports both Kafka and Amazon Kinesis as ingestion sources, making it possible for OpenSearch to consume data directly from these durable streams.
Stream Poller: To continuously fetch data from these streams, OpenSearch introduces a component called the StreamPoller. The StreamPoller is responsible for pulling records from Kafka partitions or Kinesis shards and feeding them into the indexing pipeline. Rather than waiting for applications to push data, OpenSearch actively consumes messages at its own pace, giving it greater control over ingestion rates and system stability.
One-to-One Mapping Between Shards and Streams
Each OpenSearch shard maps directly to a stream partition. For example:
OpenSearch Shard 0 → Kafka Partition 0
OpenSearch Shard 1 → Kafka Partition 1
OpenSearch Shard 2 → Kafka Partition 2This creates predictable ownership and simplifies ingestion.
Rethinking Durability (Do We Still Need a Translog?)
In a traditional OpenSearch setup, every write first goes through a translog (transaction log). Think of it as a write-ahead log that temporarily stores changes before they are fully committed to the index. If a node crashes before the data is persisted, the translog helps recover those uncommitted operations.
But Uber realized something interesting.
In a pull-based architecture, Kafka is already acting as a durable source of truth. Every event is safely stored in Kafka and can be replayed whenever necessary. This means OpenSearch no longer needs to maintain a separate durability layer for the same data.
To take advantage of this, Uber introduced a specialized IngestionEngine that replaces the traditional translog with a no-op translog manager. Instead of relying on OpenSearch for durability, the responsibility is delegated to Kafka, which already stores and retains the complete event stream.
This change simplifies the indexing pipeline and reduces several overheads, including additional disk writes, storage consumption, and write amplification. At the same time, durability guarantees remain intact because any lost data can always be recovered by replaying events from Kafka.
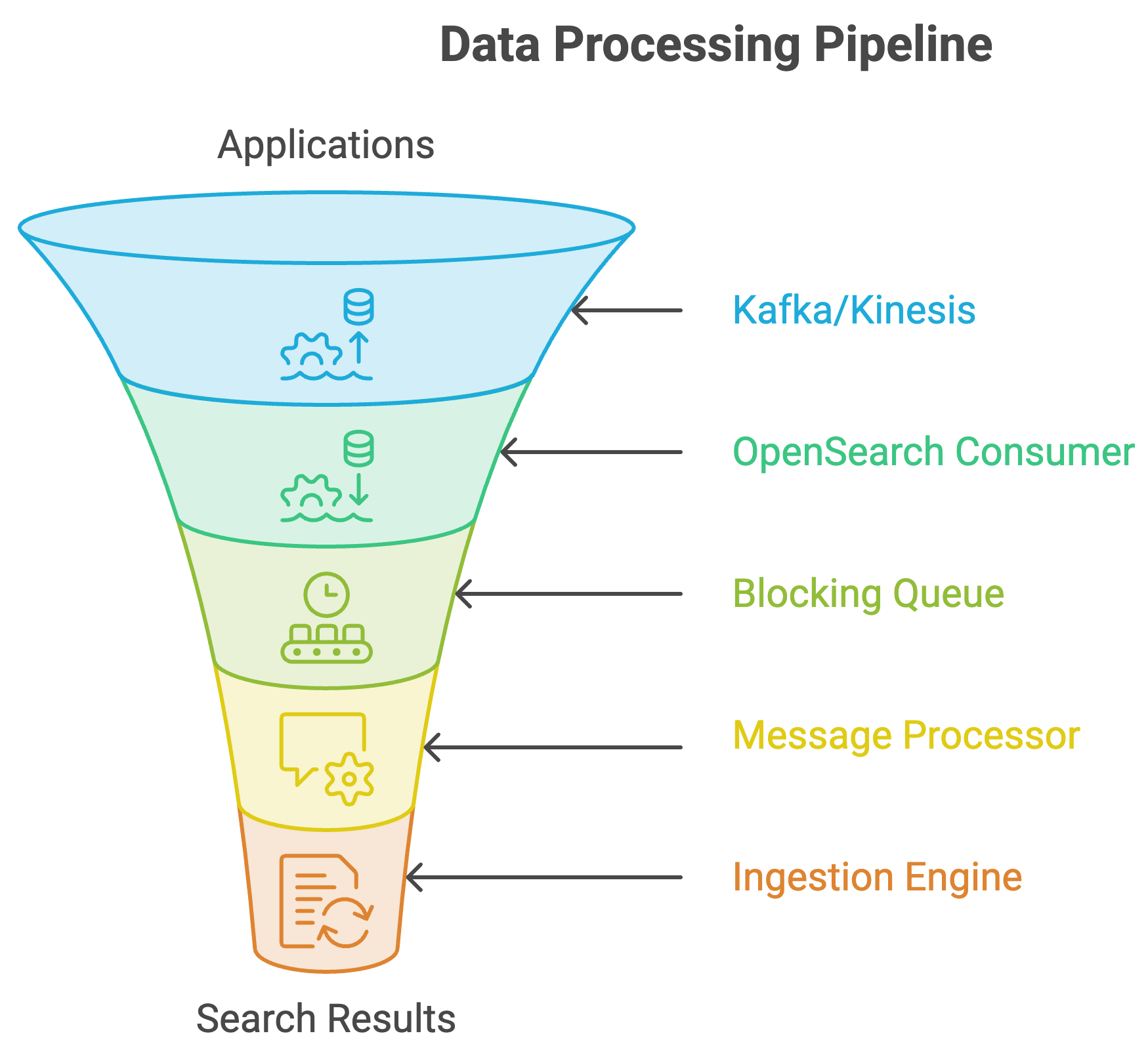
How the Data Flows Through the System
Now that we've looked at the architecture, let's see what happens when a new event enters the system. Let's follow a message from creation to indexing.

Step 1: Data Is Produced
Applications publish events into:
Kafka topics
Kinesis streams
These streaming systems persist data and allow replay when needed.
Step 2: Stream Consumer Pulls Messages
A consumer running inside OpenSearch continuously pulls new records. Each primary shard owns its own consumer. The consumer writes incoming records into a blocking queue.
Step 3: Blocking Queue Buffers Work
The blocking queue serves an important purpose. It decouples:
Message consumption
Message processing
This improves throughput because consumers can continue pulling while processors are working.
Step 4: Message Processing
A dedicated processor thread:
Validates messages
Transforms data
Creates indexing requests
These requests are then sent to the ingestion engine.
Step 5: Documents Are Indexed
Finally, the IngestionEngine:
Adds documents
Updates documents
Deletes documents
inside the Lucene index that powers OpenSearch.
What Happens When a Shard Fails?
Removing the translog creates a challenge. So, How do you recover after a failure? Uber solved this using something called a BatchStartPointer.
Every commit stores: The earliest offset currently being processed. This offset acts as a safe checkpoint.
When a primary shard fails:
A replica becomes the new primary
The checkpoint is retrieved
Kafka consumption rewinds to that offset
Messages are replayed
Already indexed documents are skipped using versioning
This ensures no data is lost and no duplicate indexing.
Handling Out-of-Order Events
Real-world systems rarely deliver messages perfectly in order. Events can arrive late because of:
Network latency
Producer retries
Cross-region replication
Without protection, an older update could overwrite a newer one. To prevent this, pull-based ingestion supports external versioning. Each message can include a version number. The latest version always wins, ensuring data consistency.
Handling Failures During Ingestion
In real-world systems, not every message can be processed successfully. Failures can happen due to invalid schemas, transformation errors, or bugs in the processing logic. To handle these situations, pull-based ingestion provides two different error-handling strategies.
Drop Policy is the simpler and more commonly used approach. If a message fails during processing, it is discarded and the consumer continues processing subsequent messages. Uber recommends this policy for most indexing workloads since the next version of a document typically contains the latest state and can safely overwrite older data.
Block Policy, on the other hand, takes a stricter approach. If a message fails, the consumer keeps retrying that message indefinitely and stops processing any subsequent messages from that source partition. This is useful for workloads where every single message is critical and skipping even one update is unacceptable.
Two Ways OpenSearch Handles Ingestion
Pull-based ingestion supports two operating modes, each optimized for a different goal.
Segment Replication Mode: This is the default mode. Here, only the primary shard consumes data from Kafka and performs the indexing work. Once the Lucene segments are created, replica shards simply download those completed segments.
Since indexing happens only once, this approach is more efficient and consumes less CPU. The tradeoff is a small replication delay, as replicas need time to receive the latest segments.
All-Active Mode: In All-Active mode, every shard copy including replicas consumes data directly from Kafka and builds its own index independently.
This eliminates most replication delay and makes updates visible much faster across the cluster. However, because every shard performs the indexing work, compute costs are significantly higher. In simple terms, the system trades efficiency for fresher data.
How Uber Uses This Globally
Uber operates search clusters across multiple regions. For business continuity, every region must maintain a complete and up-to-date view of global data.
The architecture looks like this:
Regional Producers
↓
Regional Kafka Topics
↓
Cross-Region Kafka Replication
↓
Global Aggregated Topics
↓
Regional OpenSearch ClustersEach OpenSearch cluster independently consumes from the same global Kafka streams.
This provides two major benefits:
High Availability: If one region fails, another region already has a complete copy of the data.
Global Consistency: Users receive the same search results regardless of which region serves the request.
What's Next for Uber?
Uber has already started migrating smaller use cases to pull-based ingestion. The long-term goal is much bigger: Move all search workloads to a cloud-native OpenSearch architecture built around pull-based ingestion.
Future improvements include:
Concurrent pollers for higher throughput
Priority-aware ingestion
Better scalability
Improved resilience
Takeaways
Traditional push-based indexing becomes difficult to manage at massive scale due to traffic spikes, replay challenges, and operational complexity.
Uber adopted a pull-based ingestion model where Kafka acts as the durable buffer, allowing OpenSearch to consume data at its own pace.
By treating Kafka as the source of truth, Uber simplified recovery, improved reliability, and eliminated the need for complex replay mechanisms.
The architecture enables Uber to handle ingestion spikes gracefully, recover from failures reliably, and maintain a consistent global view of data across regions.
The biggest lesson is that decoupling data producers from search clusters can significantly improve scalability, resilience, and operational efficiency.
Official blog from Uber: How Uber Indexes Streaming Data with Pull-Based Ingestion in OpenSearch™
By now, you must have had a clear idea of, How Uber Uses Pull-Based Ingestion to Keep Search Data Fresh at Massive Scale? In a nutshell, Uber replaced traditional push-based indexing with a pull-based ingestion model where OpenSearch consumes data from Kafka at its own pace. This improved scalability, simplified recovery, and enabled globally consistent search across multiple regions.
Congratulations! You've just advanced another step in your tech journey. Keep progressing!
Rohit Lakhotia
Rohit Lakhotia is a software engineer and writer covering engineering, career growth, and the tech industry.